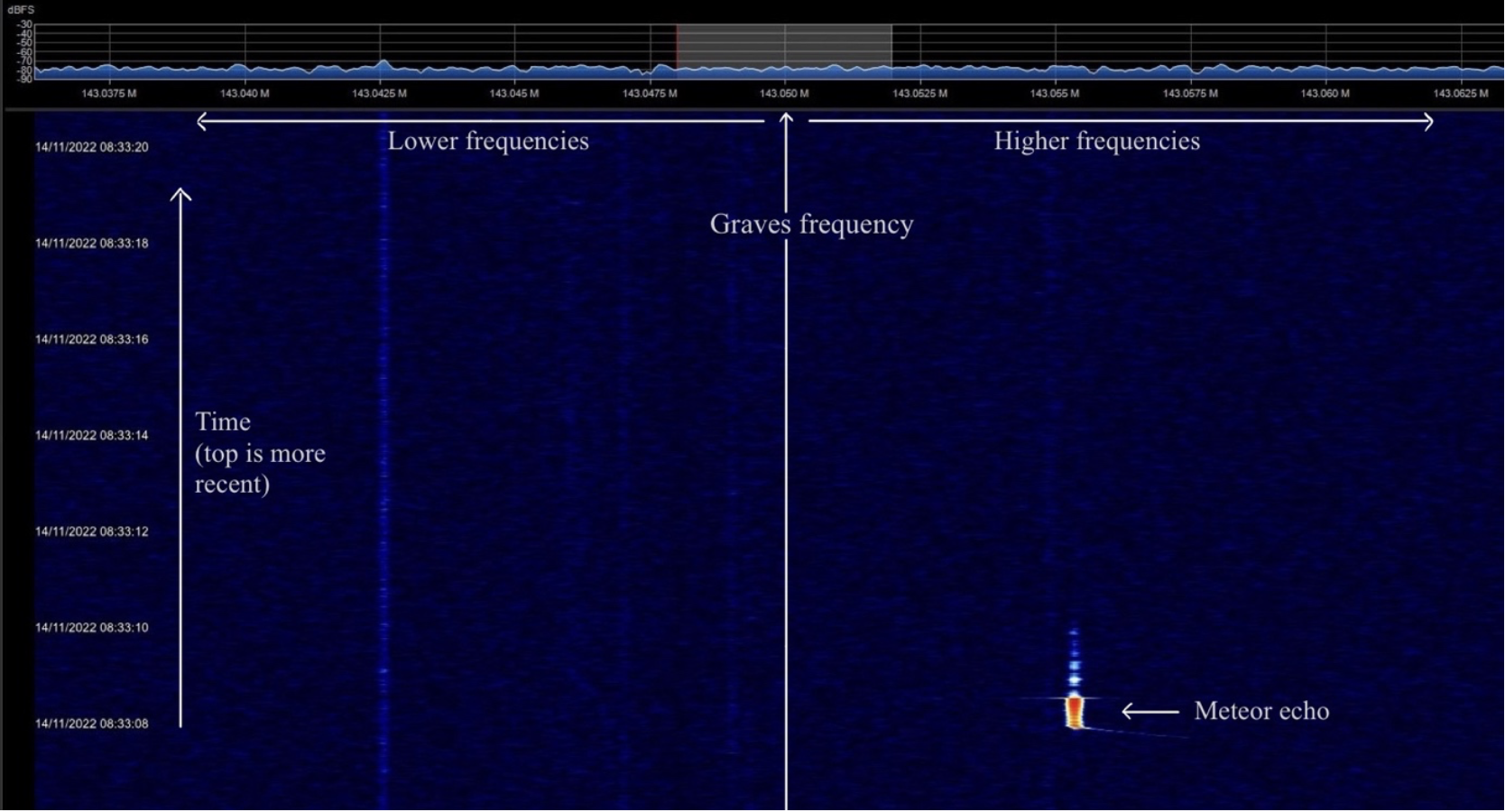
.container {
display: flex;
justify-content: center;
align-items: center;
}
img {
margin: 10px;
max-width: 130%;
height: auto;
}
Context
Today marks the longest government lockdown in government history.
This shutdown has hit energy hard, with soaring prices and delays on energy production projects. At the same time, there is a huge conversation around meeting electricity demands of power hungry AI by building more data centers, and the impact that has on local communities. There are dozens of other conversations happening in the energy space and this is what my group was interested in looking at and how the recent change in political power has shifted these conversations.
The data for this project is almost 5000 articles from the same time windows in 2024 and 2025: spanning from February to July. Did some standard preprocessing for text, removed stopwords, punctuation and tokenized the data. We ended up with
Extract articles from txt files.
Each raw news text file was compliled by taking multiple energy articles from the same day scaped from the web. As a result, a lot of these files end up hacing inconsistent spacing and formatting, as well as relics from the web interface. Luckily I had a list of all article titles at hand that i could utilize, but they were not always an exact match to the text. In order to segment the articles accurately, I tried implementing fuzzy string matching (Levenshtein distance) to align detected titles with known article headers. I managed to successfully link about 2,859 of 4,751 titles. After segmentation, articles underwent standard NLP preprocessing: tokenization, stopword and punctuation removal, and exclusion of filler journalistic terms (e.g., “said,” “reported”), resulting in a clean, comparable corpus suitable for topic modeling.
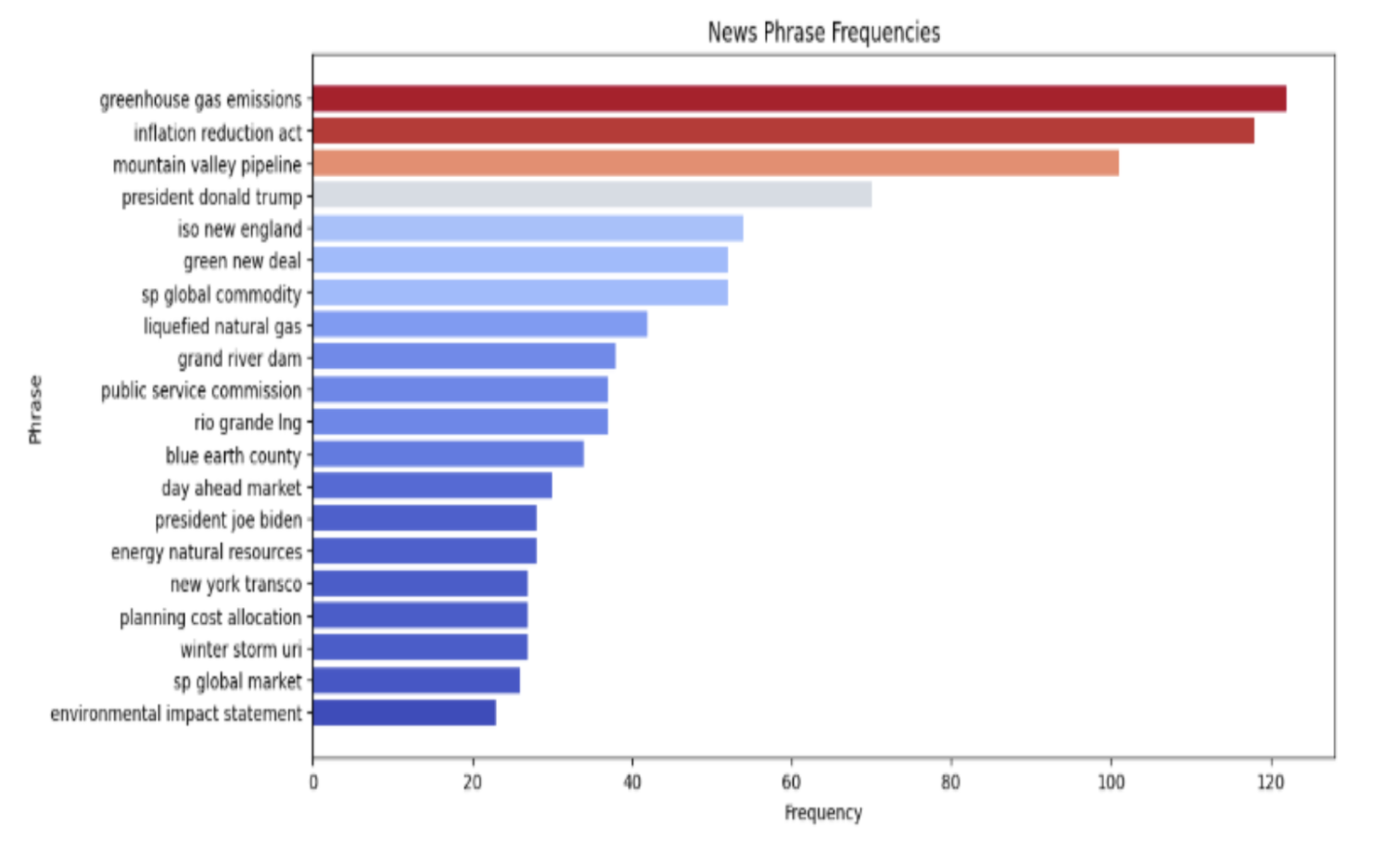
Here we see some of the top word trigrams visualized. This help us contextualize what we 3 words phrases we typically see in these articles, which can help us later with our topic analysis.
Using LDA as a baseline
Latend Dirichlet Allocation (not to be confused with Linear Discriminant analysis) is a topic modelling technique that uses Bayesian modelling to cluster words into topics. In other words, it assumes that given a corpus of words, each word can be allocated to a discrete set of topics. As you can imagine, the number of topics chosen is important, it affects how cohesive the topics are.
The best method for topic number selection is using a key metric, plotting its value for a chosen range of possible topic numbers, and see where this value plateaus, where adding new topics offers no better value. I chose Topic Coherece, a measure of how similar words within a topic are.

Interestingly, the coherence score reaches a peak at 12 topics and then steadily goes down. These values are not dramatically different, as a C_V score in the range of 0.5-0.59 is considered decent, but it is not the behavior we expect. This sharp decrease in performance could be due to the fact that our corpus is exclusively concerning energy news, so there is a lot of overlap in the topics discussed. In a different topic modelling scenario, e.g. modelling research papers: we would end up getting very distinct topics such as History, Physics, Anthropology, Political Science etc. Here, we reach a limit where no more specificity can be achieved, as each word has been allocated to a redundant subtopic that does not offer any more nuance. In our case, the energy news corpus is lexically and conceptually dense, with few truly distinct themes, after 12 topics the model keeps slicing coherent topics into smaller, overlapping pieces, which coherence penalizes it harshly.
Another way however to evaluate our choice for number of topics is to check the topic:
This approach uncovers another aspect of LDA, topics may have similar meaning between each other, yielding a high coherence score, but they may also have a lot of overlap. This graph is from gensim’s package pyLDAvis, its a great tool to visualize topic similarity!
It utilies the relevance of a word w to a topic t, calculated as:
\[r(w, t \mid \lambda) = \lambda \, p(w \mid t) + (1 - \lambda) \, \frac{p(w \mid t)}{p(w)}\]
Here, λ (lambda) controls the balance between how frequent and how distinctive a term is:
- λ = 1 → ranks words by how common they are within the topic (general terms).
- λ = 0 → ranks words by how unique they are to that topic (specific terms).
- λ ≈ 0.6 (default) → balances both views for interpretability.
We see here that a 12 topic LDA is insufficient, we have a lot of topic overlap; topic 4 and topic 5 are virtually the same, covering renewable energy projects and climate change related words. So in order to balance high coherence with topic uniqueness I chose 10 topics, and plotted this instead;
Here we see that with nine topics a much better separated topics, so we are sticking with 9. Here are some words from the topics:
| Topic ID |
Top Terms |
Likely Theme / Interpretation |
| 0 |
bill, house, republican, senate, tax, trump, committee, credit, democrat, budget |
Federal policy and legislation |
| 1 |
data, plant, demand, coal, nuclear, center, price, july, generation, reactor |
Data centers, power generation, and nuclear demand |
| 2 |
agency, rule, court, epa, environmental, trump, ferc, climate, order, law |
Regulation, courts, and environmental policy |
| 3 |
ferc, transmission, order, utility, rate, miso, market, proposal, pjm, process |
Transmission and FERC regulatory orders |
| 4 |
dam, water, river, pipeline, county, safety, area, lake, land, million |
Infrastructure, water resources, and safety |
| 5 |
capacity, market, gw, mw, pjm, demand, load, price, generation, solar |
Grid capacity, markets, and generation |
| 6 |
utility, transmission, electricity, solar, demand, line, system, wind, data, center |
Utilities, electrification, and renewables |
| 7 |
lng, export, pipeline, wind, facility, global, offshore, million, terminal, permit |
LNG exports and offshore energy infrastructure |
| 8 |
tariff, trump, lng, market, trade, oil, april, global, supply, import |
Trade, tariffs, and global energy markets |
What stands out in these topics is how the vocabulary of energy policy reflects both technical and political worlds.
The model doesn’t just surface buzzwords, it sketches the infrastructure of how the U.S. talks about power itself.
On one side, we see the hard engineering lexicon: words like transmission, capacity, load, generation, pipeline, and LNG anchor discussions in the physical systems that move electrons and fuel.
These are the operational conversations, the ones about keeping the grid stable, expanding transmission lines, or meeting demand from new data centers.
On the other side sits the language of governance and law: bill, house, committee, court, rule, EPA, order.
This vocabulary reveals that energy is never just a technical challenge; it’s also a legislative and judicial process.
Policy and legal terms intermingle with industry keywords, reminding us that decisions about pipelines or nuclear reactors are made as much in congressional committees and courtrooms as in control rooms.
That overlap — between ferc, trump, epa, rule, and market — captures a particularly modern dynamic:
the way energy debates intersect with climate regulation, trade policy, and even global supply chains.
In other words, the “energy transition” isn’t just happening in the grid — it’s happening in the rhetoric that shapes how we understand and argue about it.
Beyond static interpretation, these topics also open the door to temporal comparison.
The most prominent theme, our federal and legislative energy policy topic, shows a noticeable decline in frequency over time, dropping from nearly 0.20 to about 0.15 in share. This pattern makes sense when viewed in the context of the 2025 administration change. In the months leading up to January, media attention was dominated by speculation around how new leadership might reshape national energy strategy. After the transition, however, discussion slowed, reflecting a pause as the administration’s policies began to take shape.
Meanwhile, coverage related to data centers and nuclear generation increased significantly between 2024 and 2025. This rise closely follows the surge in AI adoption and the corresponding spike in electricity demand. As questions about how to power the next wave of AI dominated headlines, nuclear energy began to reemerge as a central part of that conversation. With the new administration openly backing expanded nuclear production and new projects nationwide, the media narrative shifted toward emphasizing capacity growth, energy security, and technological reliability.
In contrast, topics focused on environmental policy declined sharply. This suggests that climate and sustainability have taken a quieter role in the national energy dialogue, likely displaced by more immediate economic and industrial priorities. Similarly, mentions of utilities, renewables, LNG, and offshore development all decreased, reflecting a broader pivot away from decarbonization and toward supply-side concerns such as grid stability and generation capacity.
Other areas, however, have become more prominent. Coverage surrounding FERC orders rose in intensity, underscoring the growing regulatory attention to managing grid reliability and adapting to new forms of generation. Water infrastructure also gained visibility, likely reflecting growing concern about the resource strain that large-scale data centers and energy production place on local ecosystems.
Finally, discussions of tariffs and trade policy saw renewed activity, particularly around Trump-era tariffs and their implications for energy technology imports and domestic production.
Taken together, these shifts tell a clear story: the public and media conversation has turned from long-term environmental ambitions toward short-term energy security and infrastructure resilience. The period from 2024 to 2025 marks not just a political transition, but a fundamental reframing of the energy narrative — one now centered on power capacity, regulation, and the balance between technological ambition and sustainable supply.
Final Thoughts
Taken together, these shifts tell a clear story: the public and media conversation has turned from long-term environmental ambitions toward short-term energy security and infrastructure resilience. The period from 2024 to 2025 marks not just a political transition, but a fundamental reframing of the energy narrative, one now centered on power capacity, regulation, and the balance between technological ambition and sustainable supply.
This analysis is still in progress, some next steps will include:
- Performing sentiment analysis: There are a lot of overlapping topics in 2024 and 2025, it would be interesting to see if they are spoken about in a different light.
- Creating a web app: a dashboard with more information about the energy space for a broader audience, potentially including a RAG chat bot that answers frequent energy related questions.
]]>